تعارف
ٹیکسٹ پروسیسنگ کے وسیع ڈومین میں اسٹرنگ مماثلت ایک بہت اہم مضمون ہے۔ سٹرنگ سے ملنے والی الگورتھم بنیادی اجزاء ہیں جو زیادہ تر آپریٹنگ سسٹم کے تحت موجود عملی سافٹ ویروں کے نفاذ میں استعمال ہوتے ہیں۔ مزید یہ کہ وہ پروگرامنگ کے ان طریقوں پر زور دیتے ہیں جو کمپیوٹر سائنس (سسٹم یا سافٹ ویئر ڈیزائن) کے دیگر شعبوں میں مثال کے طور پر کام کرتے ہیں۔ آخر میں ، وہ مشکل مسائل پیش کرکے نظریاتی کمپیوٹر سائنس میں بھی اہم کردار ادا کرتے ہیں۔
اگرچہ اعداد و شمار کو مختلف طریقوں سے حفظ کیا جاتا ہے ، لیکن معلومات کا تبادلہ کرنے کے لئے متن بنیادی شکل بنی ہوئی ہے۔ یہ خاص طور پر ادب یا لسانیات میں واضح ہوتا ہے جہاں ڈیٹا بہت بڑا کارپس اور لغت پر مشتمل ہوتا ہے۔ اس کا اطلاق کمپیوٹر سائنس پر بھی ہوتا ہے جہاں بڑی تعداد میں ڈیٹا لکیری فائلوں میں محفوظ ہوتا ہے۔ اور یہ معاملہ بھی ہے ، مثال کے طور پر ، مالیکیولر بیالوجی میں کیونکہ حیاتیاتی انو اکثر نیوکلیوٹائڈس یا امینو ایسڈ کی ترتیب کے طور پر قریب آسکتے ہیں۔ مزید یہ کہ ان شعبوں میں دستیاب اعداد و شمار کی مقدار ہر اٹھارہ ماہ بعد دوگنی ہوتی ہے۔ یہی وجہ ہے کہ الگورتھم کو موثر ہونا چاہئے یہاں تک کہ اگر کمپیوٹر کی ذخیرہ کرنے کی رفتار اور صلاحیت مستقل طور پر بڑھ جاتی ہے۔
سٹرنگ کا ملاپ ایک متن میں ایک یا زیادہ عام طور پر سٹرنگ کے تمام واقعات (جسے عام طور پر پیٹرن کہا جاتا ہے ) ڈھونڈتا ہے ۔ اس کتاب میں موجود تمام الگورتھم متن میں موجود نمونوں کے تمام واقعات کو ظاہر کرتے ہیں۔ پیٹرن کو x = x [0 .. m -1] کے ذریعہ بیان کیا گیا ہے؛ اس کی لمبائی میٹر کے برابر ہے ۔ متن کو y = y [0 .. n -1] کے ذریعہ بیان کیا گیا ہے؛ اس کی لمبائی n کے برابر ہے ۔ دونوں ڈور کردار کی ایک محدود سیٹ کے اوپر تعمیر ایک بلایا ہیں حروف تہجی کی طرف سے denoted سائز کے برابر ہے کے ساتھ .

درخواستوں کو دو قسم کے حل کی ضرورت ہوتی ہے جس پر منحصر ہے کہ کس تار ، نمونہ یا متن کو پہلے دیا جاتا ہے۔ پیٹرن کو پہلے سے بڑھاوا دینے اور پہلی قسم کی پریشانی کے حل کے ل auto آٹو میٹا یا تاروں کے امتزاج خصوصیات کے استعمال پر مبنی الگورتھم عام طور پر نافذ کیا جاتا ہے۔ درختوں یا آٹو میٹا کے ذریعہ پائے جانے والے اشاریہ کے تصور کو دوسری طرح کے حل میں استعمال کیا جاتا ہے۔ یہ کتاب صرف پہلی قسم کے الگورتھمز کی تحقیقات کرے گی۔
موجودہ کتاب کے اسٹرنگ مماثل الگورتھم مندرجہ ذیل ہیں۔ وہ ونڈو کی مدد سے متن کو اسکین کرتے ہیں جس کا سائز عام طور پر میٹر کے برابر ہوتا ہے ۔ وہ پہلے ونڈو اور متن کے بائیں سروں کو سیدھ کرتے ہیں ، پھر کھڑکی کے حرفوں کو پیٹرن کے حروف سے موازنہ کرتے ہیں – اس مخصوص کام کو ایک کوشش کہا جاتا ہے – اور پیٹرن کے پورے میچ کے بعد یا کسی مماثلت کے بعد وہ اس شفٹ کو منتقل کرتے ہیں۔ دائیں طرف ونڈو. جب تک دریچہ کے دائیں سرے سے متن کے دائیں سرے سے آگے نہیں جاتا تب تک وہ دوبارہ اسی عمل کو دہراتے ہیں۔ اس میکانزم کو عام طور پر سلائڈنگ ونڈو میکانزم کہا جاتا ہے ۔ جب ہم ونڈو کو پوزیشن میں رکھتے ہیں تو ہم ہر کوشش کو ٹیکسٹ میں پوزیشن j کے ساتھ منسلک کرتے ہیںy [ j .. j + m-1 ]۔
جانور فورس الگورتھم کے تمام واقعات سے locates ایکس میں Y وقت O (میں MN ). جانوروں کے طاقت کے طریقہ کار میں بہت ساری بہتریوں کو درجہ بندی کیا جاسکتا ہے جس کے مطابق انہوں نے پیٹرن حروف اور متن کے حروف اور ہر کوشش کے موازنہ کو ترتیب دیا ہے۔ چار قسمیں پیدا ہوتی ہیں: موازنہ کرنے کا سب سے قدرتی طریقہ بائیں سے دائیں تک ہے ، جو پڑھنے کی سمت ہے۔ دائیں سے بائیں موازنہ کرنا عام طور پر عملی طور پر بہترین الگورتھم کی طرف جاتا ہے۔ بہترین نظریاتی حدود اس وقت پہنچ جاتے ہیں جب موازنہ ایک خاص ترتیب میں کیا جاتا ہے۔ آخر میں کچھ الگورتھم موجود ہیں جس کے لئے موازنہ کرنے کا حکم متعلقہ نہیں ہے (ایسا ہی بروٹ فورس الگورتھم ہے)۔بائیں سے دائیں
ہیشنگ ایک ایسا آسان طریقہ مہیا کرتا ہے جو زیادہ تر عملی حالات میں چہارشنبہی کرداروں کی موازنہ سے پرہیز کرتا ہے ، اور جو مناسب امکانی قیاسات کے تحت خطوطی وقت پر چلتا ہے۔ اسے ہیریسن نے متعارف کرایا ہے اور بعد میں کارپ اور رابین نے مکمل تجزیہ کیا ہے ۔
یہ فرض کرتے ہوئے کہ پیٹرن کی لمبائی اب مشین کے میموری ورڈ سائز سے زیادہ نہیں ہے ، شفٹ یا الگورتھم عین مطابق تار ملانے والے مسئلے کو حل کرنے کے لئے ایک موثر الگورتھم ہے اور یہ آسانی سے تار کے ملاپ کے مسائل کی وسیع حد تک آسانی سے ڈھل جاتا ہے۔
پہلی لکیری ٹائم سٹرنگ سے ملنے والا الگورتھم مورس اور پراٹ سے ہے ۔ اس میں ناتھ ، مورس اور پراٹ نے بہتری لائی ہے ۔ تلاش آٹو میٹن کے ذریعہ پہچاننے کے عمل کی طرح برتاؤ کرتی ہے ، اور متن کے ایک کردار کا موازنہ پیٹرن کے ایک کردار سے کیا جاتا ہے جو لاگ ( ایم +1) سے زیادہ نہیں ![]() ہے ( سنہری تناسب ہے
ہے ( سنہری تناسب ہے 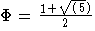 )۔ ہینکارٹ نے ثابت کیا کہ سائمن کے ذریعہ دریافت کردہ متعلقہ الگورتھم کی اس تاخیر سے ہر متن کے 1 + لاگ 2 میٹر موازنہ نہیں کیے جاتے ہیں۔ وہ تین الگورتھم بدترین حالت میں زیادہ سے زیادہ 2 ن -1 ٹیکسٹ کریکٹر موازنہ پر انجام دیتے ہیں ۔
)۔ ہینکارٹ نے ثابت کیا کہ سائمن کے ذریعہ دریافت کردہ متعلقہ الگورتھم کی اس تاخیر سے ہر متن کے 1 + لاگ 2 میٹر موازنہ نہیں کیے جاتے ہیں۔ وہ تین الگورتھم بدترین حالت میں زیادہ سے زیادہ 2 ن -1 ٹیکسٹ کریکٹر موازنہ پر انجام دیتے ہیں ۔
ایک ساتھ تلاش نیتاتمک تبدوست خودکار بالکل انجام دیتا ن متن کردار معائنہ لیکن یہ O (میں ایک اضافی جگہ کی ضرورت ہوتی میٹر ). فارورڈ Dawg کی میچنگ الگورتھم کارکردگی بالکل پیٹرن کی لاحقہ خودکار استعمال کرتے ہوئے متن کردار معائنہ کے اسی تعداد.
Apostolico-Crochemore الگورتھم ایک سادہ الگورتھم جس کارکردگی کا مظاہرہ ہے  ن متن کردار موازنہ بدترین صورت میں.
ن متن کردار موازنہ بدترین صورت میں.
ناٹ نو بولی الگورتھم ایک چکنی حد تک بدترین صورت وقت کی پیچیدگی کے ساتھ ایک بہت ہی آسان الگورتھم ہے لیکن اس میں مستقل وقت اور جگہ میں پہلے سے طے شدہ مرحلے کی ضرورت ہوتی ہے اور اوسط صورت میں قدرے ذیلی خطیر ہوتا ہے۔دائیں سے بائیں
BOYER-مور الگورتھم معمول کی ایپلی کیشنز میں سب سے زیادہ موثر سٹرنگ کے ملاپ کے الگورتھم کے طور پر تصور کیا جاتا ہے. اس کا ایک آسان ورژن (یا پورا الگورتھم) اکثر “سرچ” اور “متبادل” کمانڈوں کے لئے ٹیکسٹ ایڈیٹرز میں نافذ کیا جاتا ہے۔ کول نے ثابت کیا کہ غیر متواتر پیٹرن کے ل prep پری پروسیسنگ کے بعد زیادہ سے زیادہ کردار موازنہ 3 ن کی پابند ہے۔ وقتاic فوقتا. نمونوں کے ل It اس میں چوکور بدترین صورتحال ہے۔
بوئیر مور الگورتھم کی متعدد اقسام اس کے چکنی چال چلن سے گریز کرتی ہیں۔ علامت موازنہ کی تعداد کے لحاظ سے انتہائی موثر حل اپوسٹولکو اور گیانکارلو ، کروچیمور ایٹ علی ( ٹربو بی ایم ) ، اور کولسی ( ریورس کالوسی ) نے تیار کیے ہیں۔
تجرباتی نتائج سے پتہ چلتا ہے کہ بوئیر اور مور کے الگورتھم کی مختلف حالتوں کو اتوار ( فوری تلاش ) کے ذریعہ ڈیزائن کیا گیا ہے اور کروچیمور ایٹ الی ( ریورس فیکٹر اور ٹربو ریورس فیکٹر ) کے لاحقہ آٹومیٹن پر مبنی ایک الگورتھم عملی طور پر سب سے زیادہ موثر ہے۔
جھو اور Takaoka اور بیری-Ravindran الگورتھم BOYER-مور الگورتھم کے ایڈیشن میں ایک اضافی جگہ کی ضرورت ہوتی ہے جس کے ہیں O ( 2 ).ایک خاص ترتیب میں
پہلے دو لکیری زیادہ سے زیادہ خلائی سٹرنگ سے ملنے والے الگورتھم گیل سیفیرس اور کروچیمور پیرن ( دو طرفہ الگورتھم) کی وجہ سے ہیں۔ وہ پیٹرن کو دو حصوں میں تقسیم کرتے ہیں ، وہ پہلے سے پیٹرن کے دائیں حصے کو بائیں سے دائیں تک تلاش کرتے ہیں اور پھر اگر کوئی مماثلت نہیں ہوتی ہے تو وہ بائیں حصے کی تلاش کرتے ہیں۔
کولسی اور گیل -گیان کارلو کے الگورتھم نے پیٹرن کی پوزیشنوں کو دو حصوں میں تقسیم کیا۔ وہ پہلے ان نمونہ حروف کی تلاش کرتے ہیں جن کی پوزیشن پہلے سب سیٹ میں بائیں سے دائیں تک ہوتی ہے اور پھر اگر کوئی میل جول پیدا نہیں ہوتا ہے تو وہ بائیں سے دائیں تک باقی کرداروں کی تلاش کرتے ہیں۔ Colussi الگورتھم زیادہ سے زیادہ Knuth-مورس-پراٹ الگورتھم اور کارکردگی پر ایک بہتر ہے ن بدترین صورت میں متن کردار موازنہ. گلیل-سے Giancarlo الگورتھم جو اسے زیادہ سے زیادہ انجام دینے کے لئے کے قابل بناتا ہے ایک خصوصی معاملے میں Colussi الگورتھم کو بہتر بناتا 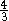 ن بدترین صورت میں متن کردار موازنہ.
ن بدترین صورت میں متن کردار موازنہ.
اتوار کا زیادہ سے زیادہ مساوی میچ اور زیادہ سے زیادہ شفٹ الگورتھم نمونہ کی پوزیشنوں کو بالترتیب ان کی کیریکٹر فریکوئنسی اور ان کی اہم شفٹ کے مطابق ترتیب دیتے ہیں۔
سرچ چھوڑیں ، کے ایم پی اسکیپ سرچ اور الفا اسکاپ الگگوردمز بذریعہ چارس ( ایٹ الی ) متن میں پیٹرن پر ابتدائی پوزیشنوں کے تعین کیلئے بالٹیاں استعمال کریں۔کسی بھی ترتیب میں
Horspool الگورتھم کی ایک مختلف ہے BOYER-مور الگورتھم، یہ ان کی تبدیلی کی تقریب کا ایک اور جس میں حکم کا متن حرف موازنہ کارکردگی کا مظاہرہ کر رہے ہیں غیر متعلقہ ہے استعمال کرتا ہے. یہ دوسرے تمام اشکال میں بھی درست ہے جیسے اتوار کی کوئیک سرچ ، ہیوم کے اتوار کے مطابق ٹونڈ بوئیر مور ، اسمتھ الگورتھم اور رائٹا الگورتھم۔تعریفیں
ہم عملی تلاشوں پر غور کریں گے۔ ہم فرض کریں گے کہ حروف تہجی ASCII کوڈز یا اس کا کوئی سب سیٹ ہے۔ الگورتھم سی پروگرامنگ زبان میں پیش کیے جاتے ہیں ، اس طرح ایک لفظ ڈبلیو کے ل 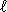 the حرف W [0]، …، w [ -1] اور w [ ] میں ایک خاص اختتام حرف (نول کریکٹر) ہوتا ہے جو کہیں بھی واقع نہیں ہوسکتا ہے۔ کسی بھی لفظ کے اندر لیکن آخر میں۔ دونوں الفاظ پیٹرن اور متن مرکزی میموری میں رہتے ہیں۔
the حرف W [0]، …، w [ -1] اور w [ ] میں ایک خاص اختتام حرف (نول کریکٹر) ہوتا ہے جو کہیں بھی واقع نہیں ہوسکتا ہے۔ کسی بھی لفظ کے اندر لیکن آخر میں۔ دونوں الفاظ پیٹرن اور متن مرکزی میموری میں رہتے ہیں۔
آئیے کچھ تعریفیں متعارف کروائیں۔
ایک لفظ U ایک ہے سابقہ ایک لفظ کے ڈبلیو وہاں موجود ایک لفظ ہے V (ممکنہ خالی) اس طرح کہ W = یووی .
ایک لفظ v ایک لفظ کا لاحقہ ہے W وہاں ایک لفظ u (ممکنہ طور پر خالی) موجود ہے جیسے ڈبلیو = یووی ۔
ایک لفظ Z ایک ہے ضمنی اسٹرنگ یا ایک subword یا ایک عنصر ایک لفظ کے ڈبلیو ہے دو الفاظ وہاں موجود یو اور V (ممکنہ خالی) اس طرح کہ W = uzv .
ایک انٹیجر p ایک لفظ ڈب کی مدت ہوتا ہے اگر i ، 0 i < m – p ، w [ i ] = w [ i + p ] کے لئے۔ کی سب سے چھوٹی مدت ڈبلیو کہا جاتا ہے مدت ، اس کی طرف سے لکھا جاتا ہے فی ( W ).
اگر اس کی سب سے چھوٹی مدت کی لمبائی چھوٹی ہو یا اس کے برابر ہو تو / 2 کی لمبائی کا لفظ W متواتر ہوتا ہے ، ورنہ یہ غیر متواتر ہوتا ہے ۔
ایک لفظ W ہے بنیادی وہاں موجود کوئی لفظ: یہ ایک اور لفظ کی ایک طاقت کے طور پر لکھا نہیں کر سکتے تو جا Z اور کوئی عددی K اس طرح کہ W = Z K .
ایک لفظ Z ایک ہے سرحد ایک لفظ کے ڈبلیو دو الفاظ وہاں موجود ہے تو یو اور وی اس طرح کہ W = عوض = ZV ، Z دونوں ایک سابقہ اور لاحقہ کا ہے ڈبلیو . نوٹ کریں کہ اس معاملے میں | u | = | v | ڈبلیو کی مدت ہے .
ایک لفظ کی ریورس W لمبائی کی طرف سے denoted ڈبلیو آر کے عکس کی تصویر ہے W ؛ ڈبلیو آر = W [ -1] W [ -2] … W [1] W [0].
ڈیٹرمینسٹک فائنائٹ آٹو میٹن (ڈی ایف اے) اے ایک چوگنی ( Q ، q 0 ، T ، E ) ہے جہاں:
 | Q ریاستوں کا ایک محدود سیٹ ہے۔ |
| | Q 0 میں Q ابتدائی ریاست ہے؛ |
| | ٹی ، سب سیٹ کیو ، ٹرمینل ریاستوں کا مجموعہ ہے۔ |
| | E، (کے اپسمچی س .. ق )، ٹرانزیشن کا سیٹ ہے. |
زبان L ( A ) کی طرف سے A کی وضاحت مندرجہ ذیل مجموعہ ہے: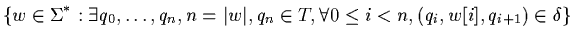
موجودہ کتاب میں پیش کردہ ہر اسٹرنگ سے مماثل الگورتھم کے ل we ہم سب سے پہلے اس کی اہم خصوصیات بتاتے ہیں ، پھر ہم نے وضاحت کی کہ وہ اپنا سی کوڈ دینے سے پہلے کیسے کام کرتا ہے۔ اس کے بعد ہم اس کے طرز عمل کو ایک عام مثال پر ظاہر کرتے ہیں جہاں x = GCAGAGAG اور y = GCATCGCAGAGATTACACTTGG ہے۔ آخر میں ہم حوالوں کی ایک فہرست دیتے ہیں جہاں قارئین الگورتھم کی مزید مفید پیشکشیں اور ثبوت تلاش کریں گے۔ ہر کوشش میں ، میچز ہلکے بھوری رنگ میں تیار کیے جاتے ہیں جبکہ مماثلت گہری بھوری رنگ میں دکھائے جاتے ہیں۔ ایک اعداد اس ترتیب کی نشاندہی کرتی ہے جس میں کردار کا موازنہ خود کار طریقے سے الگورتھمز کے علاوہ کیا جاتا ہے جہاں نمبر کی جانچ پڑتال کے بعد نمبر ریاست کی نمائندگی کرتا ہے۔
struct _cell{
int element;
struct _cell *next;
};
typedef struct _cell *List;
اس کتاب میں ہم نے سی ڈور کا استعمال اور لمبائی کی ایک تار ہے کہ فرض میٹر ایک (پر مشتمل میٹر +1) -th علامت (عام طور پر قدر ‘\ 0’ کے ساتھ تفویض). ورنہ کچھ الگورتھم نفاذ کریش ہوسکتے ہیں جب کسی سٹرنگ کے اصل آخری کردار سے بالکل آگے کسی مقام تک پہنچنے پر۔ (اس مخصوص نکتے کی نشاندہی کرنے کے لئے سافٹ ویئر ڈویلپمنٹ لیبارٹریز سے ڈیوڈ بی ٹراؤٹ کا شکریہ)۔
اس کتاب میں ، ہم کلاسیکی اوزار استعمال کریں گے۔ ان میں سے ایک عدد کی منسلک فہرست ہے۔ اس کی وضاحت سی میں درج ذیل ہوگی:
Graph newGraph(int v, int e); Graph newAutomaton(int v, int e); Graph newSuffixAutomaton(int v, int e); int newVertex(Graph g); int getInitial(Graph g); boolean isTerminal(Graph g, int v); void setTerminal(Graph g, int v); int getTarget(Graph g, int v, unsigned char c); void setTarget(Graph g, int v, unsigned char c, int t); int getSuffixLink(Graph g, int v); void setSuffixLink(Graph g, int v, int s); int getLength(Graph g, int v); void setLength(Graph g, int v, int ell); int getPosition(Graph g, int v); void setPosition(Graph g, int v, int p); int getShift(Graph g, int v, unsigned char c); void setShift(Graph g, int v, unsigned char c, int s); void copyVertex(Graph g, int target, int source);
اس انٹرفیس کا ایک ممکنہ نفاذ مندرجہ ذیل ہے۔
struct _graph {
int vertexNumber,
edgeNumber,
vertexCounter,
initial,
*terminal,
*target,
*suffixLink,
*length,
*position,
*shift;
};
typedef struct _graph *Graph;
typedef int boolean;
#define UNDEFINED -1
/* returns a new data structure for
a graph with v vertices and e edges */
Graph newGraph(int v, int e) {
Graph g;
g = (Graph)calloc(1, sizeof(struct _graph));
if (g == NULL)
error("newGraph");
g->vertexNumber = v;
g->edgeNumber = e;
g->initial = 0;
g->vertexCounter = 1;
return(g);
}
/* returns a new data structure for
a automaton with v vertices and e edges */
Graph newAutomaton(int v, int e) {
Graph aut;
aut = newGraph(v, e);
aut->target = (int *)calloc(e, sizeof(int));
if (aut->target == NULL)
error("newAutomaton");
aut->terminal = (int *)calloc(v, sizeof(int));
if (aut->terminal == NULL)
error("newAutomaton");
return(aut);
}
/* returns a new data structure for
a suffix automaton with v vertices and e edges */
Graph newSuffixAutomaton(int v, int e) {
Graph aut;
aut = newAutomaton(v, e);
memset(aut->target, UNDEFINED, e*sizeof(int));
aut->suffixLink = (int *)calloc(v, sizeof(int));
if (aut->suffixLink == NULL)
error("newSuffixAutomaton");
aut->length = (int *)calloc(v, sizeof(int));
if (aut->length == NULL)
error("newSuffixAutomaton");
aut->position = (int *)calloc(v, sizeof(int));
if (aut->position == NULL)
error("newSuffixAutomaton");
aut->shift = (int *)calloc(e, sizeof(int));
if (aut->shift == NULL)
error("newSuffixAutomaton");
return(aut);
}
/* returns a new data structure for
a trie with v vertices and e edges */
Graph newTrie(int v, int e) {
Graph aut;
aut = newAutomaton(v, e);
memset(aut->target, UNDEFINED, e*sizeof(int));
aut->suffixLink = (int *)calloc(v, sizeof(int));
if (aut->suffixLink == NULL)
error("newTrie");
aut->length = (int *)calloc(v, sizeof(int));
if (aut->length == NULL)
error("newTrie");
aut->position = (int *)calloc(v, sizeof(int));
if (aut->position == NULL)
error("newTrie");
aut->shift = (int *)calloc(e, sizeof(int));
if (aut->shift == NULL)
error("newTrie");
return(aut);
}
/* returns a new vertex for graph g */
int newVertex(Graph g) {
if (g != NULL && g->vertexCounter <= g->vertexNumber)
return(g->vertexCounter++);
error("newVertex");
}
/* returns the initial vertex of graph g */
int getInitial(Graph g) {
if (g != NULL)
return(g->initial);
error("getInitial");
}
/* returns true if vertex v is terminal in graph g */
boolean isTerminal(Graph g, int v) {
if (g != NULL && g->terminal != NULL &&
v < g->vertexNumber)
return(g->terminal[v]);
error("isTerminal");
}
/* set vertex v to be terminal in graph g */
void setTerminal(Graph g, int v) {
if (g != NULL && g->terminal != NULL &&
v < g->vertexNumber)
g->terminal[v] = 1;
else
error("isTerminal");
}
/* returns the target of edge from vertex v
labelled by character c in graph g */
int getTarget(Graph g, int v, unsigned char c) {
if (g != NULL && g->target != NULL &&
v < g->vertexNumber && v*c < g->edgeNumber)
return(g->target[v*(g->edgeNumber/g->vertexNumber) +
c]);
error("getTarget");
}
/* add the edge from vertex v to vertex t
labelled by character c in graph g */
void setTarget(Graph g, int v, unsigned char c, int t) {
if (g != NULL && g->target != NULL &&
v < g->vertexNumber &&
v*c <= g->edgeNumber && t < g->vertexNumber)
g->target[v*(g->edgeNumber/g->vertexNumber) + c] = t;
else
error("setTarget");
}
/* returns the suffix link of vertex v in graph g */
int getSuffixLink(Graph g, int v) {
if (g != NULL && g->suffixLink != NULL &&
v < g->vertexNumber)
return(g->suffixLink[v]);
error("getSuffixLink");
}
/* set the suffix link of vertex v
to vertex s in graph g */
void setSuffixLink(Graph g, int v, int s) {
if (g != NULL && g->suffixLink != NULL &&
v < g->vertexNumber && s < g->vertexNumber)
g->suffixLink[v] = s;
else
error("setSuffixLink");
}
/* returns the length of vertex v in graph g */
int getLength(Graph g, int v) {
if (g != NULL && g->length != NULL &&
v < g->vertexNumber)
return(g->length[v]);
error("getLength");
}
/* set the length of vertex v to integer ell in graph g */
void setLength(Graph g, int v, int ell) {
if (g != NULL && g->length != NULL &&
v < g->vertexNumber)
g->length[v] = ell;
else
error("setLength");
}
/* returns the position of vertex v in graph g */
int getPosition(Graph g, int v) {
if (g != NULL && g->position != NULL &&
v < g->vertexNumber)
return(g->position[v]);
error("getPosition");
}
/* set the length of vertex v to integer ell in graph g */
void setPosition(Graph g, int v, int p) {
if (g != NULL && g->position != NULL &&
v < g->vertexNumber)
g->position[v] = p;
else
error("setPosition");
}
/* returns the shift of the edge from vertex v
labelled by character c in graph g */
int getShift(Graph g, int v, unsigned char c) {
if (g != NULL && g->shift != NULL &&
v < g->vertexNumber && v*c < g->edgeNumber)
return(g->shift[v*(g->edgeNumber/g->vertexNumber) +
c]);
error("getShift");
}
/* set the shift of the edge from vertex v
labelled by character c to integer s in graph g */
void setShift(Graph g, int v, unsigned char c, int s) {
if (g != NULL && g->shift != NULL &&
v < g->vertexNumber && v*c <= g->edgeNumber)
g->shift[v*(g->edgeNumber/g->vertexNumber) + c] = s;
else
error("setShift");
}
/* copies all the characteristics of vertex source
to vertex target in graph g */
void copyVertex(Graph g, int target, int source) {
if (g != NULL && target < g->vertexNumber &&
source < g->vertexNumber) {
if (g->target != NULL)
memcpy(g->target +
target*(g->edgeNumber/g->vertexNumber),
g->target +
source*(g->edgeNumber/g->vertexNumber),
(g->edgeNumber/g->vertexNumber)*
sizeof(int));
if (g->shift != NULL)
memcpy(g->shift +
target*(g->edgeNumber/g->vertexNumber),
g->shift +
source*(g->edgeNumber/g->vertexNumber),
g->edgeNumber/g->vertexNumber)*
sizeof(int));
if (g->terminal != NULL)
g->terminal[target] = g->terminal[source];
if (g->suffixLink != NULL)
g->suffixLink[target] = g->suffixLink[source];
if (g->length != NULL)
g->length[target] = g->length[source];
if (g->position != NULL)
g->position[target] = g->position[source];
}
else
error("copyVertex");
}